








What is DEDS
Data is a key asset in modern society. Data Science, which focuses on deriving valuable insight and knowledge from raw data, is indispensable for any economic, governmental, and scientific activity. Data Engineering provides the data ecosystem (i.e., data management pipelines, tools and services) that makes Data Science possible. The European Joint Doctorate in "Data Engineering for Data Science" (DEDS) is designed to develop education, research, and innovation at the intersection of Data Science and Data Engineering. Its core objective is to provide holistic support for the end-to-end management of the full lifecycle of data, from capture to exploitation by data scientists.
DEDS
operates under the Horizon 2020 - Marie Skłodowska-Curie Innovative Training Networks (H2020-MSCA-ITN-2020) framework. It is jointly organised by Université Libre de Bruxelles (Belgium), Universitat Politècnica de Catalunya (Spain), Aalborg Universitet (Denmark), and the Athena Research and Innovation Centre (Greece). Partner organisations from research, industry and the public sector prominently contribute to the programme by training students and providing secondments in a wide range of domains including Energy, Finance, Health, Transport, and Customer Relationship and Support.
DEDS is a 3-year doctoral programme based on a co-tutelle model. A complementary set of 15 joint, fully funded, doctoral projects focus on the main aspects of holistic management of the full data lifecycle. Each doctoral project is co-supervised by two beneficiaries and includes a secondment in a partner organisation, which grounds the research in practice and validate the proposed solutions. DEDS delivers innovative training comprising technical and transversal courses, four jointly organized summer and winter schools, as well as dissemination activities including open science events and a final conference. Upon graduation, a joint degree from the universities of the co-tutelle will be awarded.
![]() This project has received funding from the European Union's Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 955895.
This project has received funding from the European Union's Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 955895.
Why DEDS
Data drives the world. Market analysts state: "Data is now a critical corporate asset. It comes from the web, billions of phones, sensors, payment systems, cameras, and a huge array of other sources, and its value is tied to its ultimate use. While data itself will become increasingly commoditized, value is likely to accrue to the owners of scarce data, to players that aggregate data in unique ways, and especially to providers of valuable analytics".
A typical data value creation chain encompasses multiple disciplines and people with different roles, of which Data Science and Data Engineering are two prominent examples. Data Science (DS) is the scientific interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from data in various forms, both structured and unstructured. Data scientists focus on extracting meaning and insight from data through analytics. They are supported in their activities by Data Engineering (DE). Data engineers design and build the data ecosystem that is essential to analytics. Data engineers are responsible for the databases, data pipelines, and data services that are prerequisites to data analysis and data science.
In setting up these pipelines and functionalities that comprise the ecosystem, data engineers are often faced with challenges posed by extreme characteristics of Big Data, defined by the Oxford English Dictionary as "data of a very large size, typically to the extent that its manipulation and management present significant logistical challenges". Addressing these challenges demand innovative technological solutions for data management, involving new architectures, policies, practices and procedures that properly manage the full data lifecycle needs of an organisation.
The Big Data Value Strategic Research & Innovation Agenda expresses the commitment of the European Commission (EC), industry and academia partners "to build a data-driven economy across Europe, mastering the generation of value from Big Data and creating a significant competitive advantage for European industry, boosting economic growth and jobs." The agenda particularly emphasises "the existence of data assets of homogenous qualities (e.g. geospatial, time series, graphs and imagery), which calls for optimizing the performance of existing core technology (e.g. querying, indexing, feature extraction, predictive analytics and visualization)," as well as "there is a need to create complex and fine-grained predictive models on heterogeneous and massive datasets such as time series or graph data... such models must be applied in real-time on large amounts of streaming data."
Recent years have witnessed the birth of novel data management tools designed to address several of the Big Data challenges, but the problems and opportunities in the data engineering and management domain to unleash the full potential of data are still greatly unexplored. What is missing is a holistic, end-to-end management of the full lifecycle of data, from their identification and capture till their exploitation by end-users, including data scientists.
The Data Engineering for Data Science (DEDS) programme aims at carrying out foundational research within the Big Data value chain to develop new technologies that improve the data management efficiency, and specifically for Data Science. DEDS will be delivered by a consortium composed of four European beneficiaries with a world-leading position in Data Management, Data Engineering, and Data Science. The consortium will be complemented by a network of partner organisations from industry and the public sector active in a wide range of disciplines, including Energy, Health, Finance, Transport, and Customer Relationship and Support. The consortium shares a vision statement:
Mission
DEDS brings together world-leading institutions with a long experience in both research and teaching collaboration and define a concrete and realistic common mission statement (MS) as follows:
- MS1: Create and effectively disseminate cross-disciplinary essential knowledge about the generation, collection, exploitation, and value-creation of data for efficient decision-making.
- MS2: Educate ethical professionals and future leaders in data-driven innovation.
- MS3: Integrate, synthesise, and transfer scientific knowledge that enables smart, sustainable, and inclusive growth, by unleashing the potential of data-driven innovation in different disciplines for addressing societal problems, such as health care, effective energy use, and transport.
- MS4: Establishing a European data management toolkit for Data Science by creating novel functionalities and feeding them back into well-established open source data processing engines (e.g., Spark and PostgreSQL) and Data Science platforms (e.g., SWAN and RapidMiner).
Objectives
The programme is designed to provide understanding and competencies (i.e., the combination of knowledge, skills, and attitudes that students develop and apply for successful learning, living and working) in the strategic area of data management and engineering for Data Science. It will prepare the graduates for a research and innovation career both in academia and, equally important, in the ICT industry and public services. In this respect, we acknowledge the relevance of the European Research Agenda Report, and commit ourselves to contribute specially to the objectives of removing barriers to the wider use of knowledge, promote wider and faster circulation of scientific ideas, as well as fully utilising gender diversity and equality. More precisely, the consortium has defined the following quantifiable objectives (O):
- O1: To produce foundational cross-disciplinary research about the generation, collection, and exploitation of large-scale data for efficient decision-making, publish it in top scientific outlets, and promote the development of novel technologies and tools. Exploitation will be ensured by integrating them in existing open source and commercial Big Data tools to enable the extraction of valuable information in industry and public services.
- O2: To educate and train talented doctoral candidates in large-scale data management and analytics, fostering the knowledge triangle between education, research, and innovation, including both technical and transferable competencies, like ethics awareness and entrepreneurial spirit.
- O3: To establish an integrated pan-European Network of Excellence in large-scale data management that promotes the creation of tools and resources, continuously monitoring their quality and adequacy to the market needs and societal challenges, and attracting excellent local and foreign researchers. It will be composed of the beneficiaries and associated partners, as well as the software toolkit, equipment and datasets.
Added Value
The originality, added value and innovative aspects of the programme can be summarised as follows:
- The first integrated and transnational doctoral programme in the domain worldwide.
- A consortium composed by leading institutions in the domain.
- Mobility involving at least two European institutions, resulting in a joint degree.
- An ambitious European-wide cross-disciplinary research agenda integrating all the research projects.
- Contribution to the creation of novel technologies by developing open source prototypes for all thesis topics.
- Technology transfer by incorporating results in open source and commercial Big Data tools (e.g., Spark, PostgreSQL, SWAN, and RapidMiner)14 enabling both DEDS beneficiaries, partner organisations, and the public to exploit the results.
- Knowledge dissemination to both the scientific community and to a larger, non-expert public.
- An open science policy through open access, open source prototypes, and open research data.
- An instrumental training programme fostering both technical and transferable competencies.
- An integrated collaboration with industrial partners, ensuring knowledge transfer and employability.
- A strong international networking aspect, promoting community building.
- Continuous monitoring of the candidates, focusing on scientific excellence and career development.
- Assessment of the programme quality through measurable Key Performance Indicators (KPIs).
Programme Overview
DEDS is a joint doctoral programme of three-year duration. In case of unforeseen difficulties, up to two additional six-month periods can be granted if (1) it is duly justified, and (2) the Candidate Progress Committee considers the completion of a Doctoral Thesis feasible within the extended period of time.
Each ESR will be enrolled in the PhD programmes at both Home and Host universities and work on an individual research project with a supervisory team consisting of at least two academic supervisors (one from Home, one from Host), complemented by one secondment supervisor from a partner organisation. Note that, for those ESRs (co-)supervised by beneficiary ARC, the doctoral degree will be awarded by academic partner UOA.
The research activity will be carried out in the Home and Host Universities, during alternate successive mobility periods, and also includes at least one secondment in a partner organisation of the consortium. The time spent in the Host University will be no less than 33% of the total duration of the studies.
Differences among ESRs in background knowledge, original skills, and interests are expected. Thus, instead of preparing a generic training programme, ESRs will have a personalised Doctoral Project Plan (DPP) created right at the beginning of their projects. The DPP builds upon their individual background and future career prospects, allowing ESRs to tailor their own research and training activities with respect to their project objectives and individual needs, and complementing core scientific competencies with innovation-related and transferable ones. The DPP will ensure the appropriate synergy and balance between research and training, following a strict timeline to complete the doctorate in three years. The DPP jointly designed by the ESR and his/her co-supervisors, must include:
- (1) Research-specific, innovation and entrepreneurship, as well as language courses
- (2) Participation in the summer and winter schools
- (3) At least three international peer-reviewed publications
The research-specific courses will be delivered by the doctoral schools at the beneficiaries, and the other courses by both the beneficiaries and the partner organisations. The DPP also describes the activities of the ESR's secondment, which aims at validating the ESR's specific research in practice and exposing the ESR to the professional world.
Training Programme
DEDS is a joint doctoral programme in which all ESRs will follow a common process, regardless of the institutions involved. The programme fosters a wide range of technical and transferable competencies (i.e., combinations of knowledge, skills, and attitudes) aiming to improve the career prospects of ESRs and to prepare innovative leaders and entrepreneurs. The doctoral programme comprises the following activities:
- Research: Doctoral candidates work on a novel research problem guided by two supervisors who will advise and train them to gradually become independent researchers.
- Doctoral courses: Courses will be chosen by each ESR individually in coordination with his/her supervisors from the list of available courses in each university. At least 30 ECTS of courses must be chosen (distributed in a minimum of 20 ECTS in research-specific courses and a minimum of 10 ECTS in the others). The list comprises Research-specific courses, Innovation and entrepreneurship courses, Methodological and communication courses, and Language courses.
- Summer and winter schools: Invited researchers and practitioners meet and challenge the ESRs. These schools, also open to the public, enable the ESRs to get international contacts in both industry and academic sectors as well as feedback on presentations of their research. The schools are network-wide events that involve both beneficiaries and partner organisations.
- Tutoring: ESRs will be involved in teaching and educational activities, such as supervising undergraduated student projects and delivering exercises and laboratory sessions. The time spent by ESRs on teaching activities will be calibrated with national regulations, resulting in a workload equivalent to that of any doctoral in the same university.
- Knowledge dissemination: Mandatory conference participation and publications allowing ESRs to present their findings, thereby familiarising themselves with essential academic practices such as peer-review and public debating.
- External cooperation: ESRs will work with domain experts at partner organisations on intersectoral problems, get experience with interdisciplinary team work, and gain transferable skills such as familiarizing themselves with cutting-edge production systems, which will also strengthen their position to a highly competitive job market.
The Road to Success
A jointly designed doctoral process described in the figure below will ensure a continuous monitoring of the ESRs.
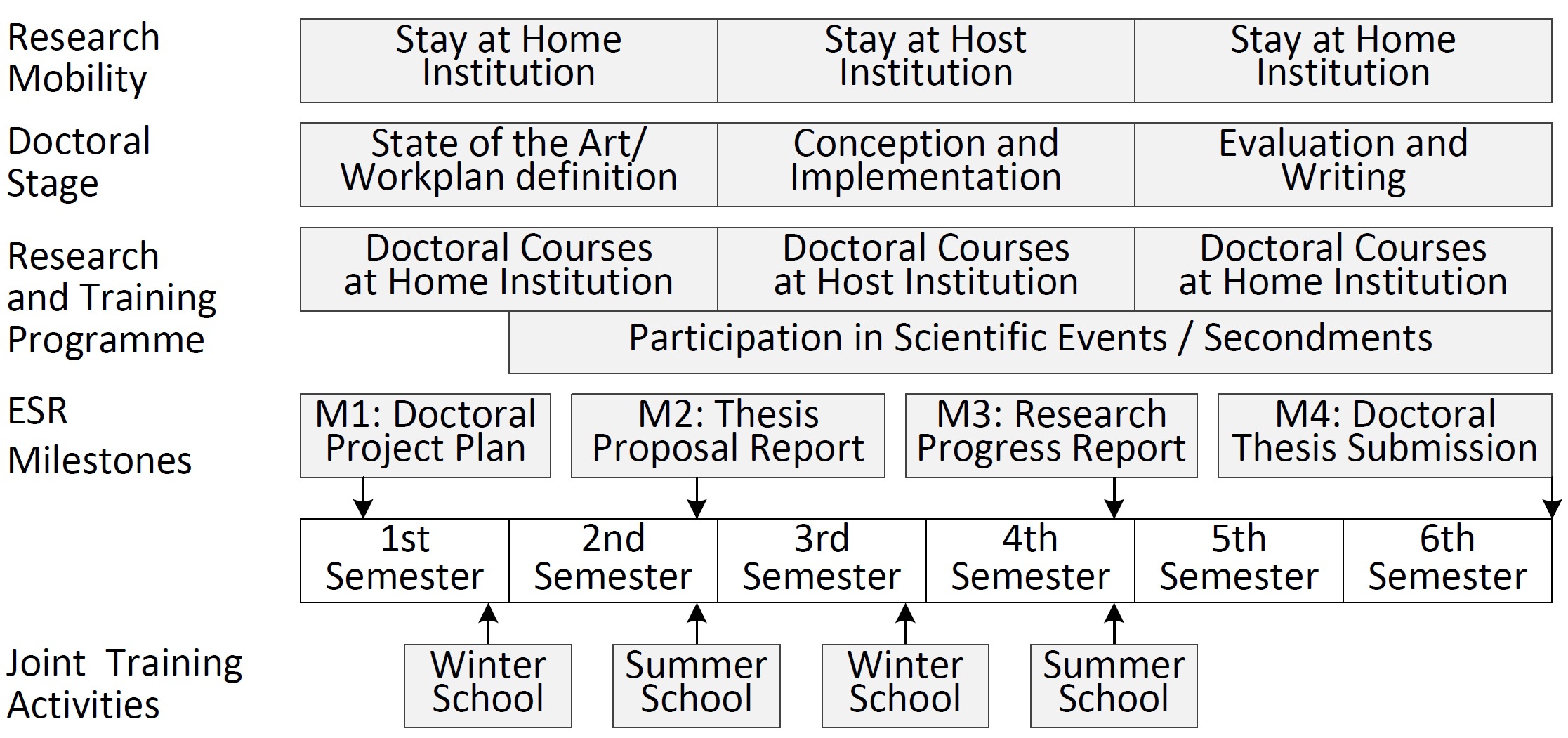
Each ESR will be involved in a Joint Doctoral Topic offered by two beneficiaries (i.e., Home and Host) with a secondment in a partner organisation. ESRs will be co-supervised by two experienced researchers using a co-tutelle model, and a third advisor with research experience from the corresponding secondment will provide ESRs an essential knowledge, experience and guidance for their future career.
To ensure a uniform evaluation, a Candidate Progress Committee (CPC) will be assigned to each ESR. The CPC consists of (1) Supervisor from Home institution; (2) Co-supervisor from Host institution; (3) Committee chair, who is a supervisor from a beneficiary distinct from the Home and Host. A secondment supervisor from a partner organisation will be invited to the CPC to provide a non-academic perspective. The CPC chair is responsible for ensuring that the process, milestones, and intermediate evaluations are met; he/she will also act as referee in case of potential disputes.
Each ESR will meet at least once every week the supervisor of the institution where he/she is located, and the other supervisor will join remotely every other week. These meetings allow ESRs to present their results, ask questions, etc. Also, periodic monitoring meetings are planned every 2.5 months between the ESR, all members of the Candidate Progress Committee (CPC), and the WP leader. These meetings should include some slides and produce minutes drafted by the ESR and reviewed by the local supervisor stating: (1) what was done since the last meeting, (2) what will be done for the next meeting, (3) what is slowing down or blocking the project, and (4) what was discovered that would be of interest, or needs to be discussed.
During the secondments, the ESRs will be supervised by an experienced researcher at the secondment partner organisation. Regular meetings with the academic supervisors will still continue during this period to ensure the coordination of the overall project.
During the joint training events, ESRs will have the opportunity to meet both supervisors face to face, allowing further synchronisation and discussion of the monitoring reports (see below) produced by the candidates.
To monitor the ESRs' progress, four milestones are defined, each accompanied by the corresponding document, which will be jointly evaluated.
- Milestone 1: Two months after the enrolment, the ESR together with his/her co-supervisors will deliver a Doctoral Project Plan (DPP), which formulates the elements involved in the research process. In addition, the DPP will specify the ESR's personalised doctoral training programme taking into account his/her previous background and future career prospects.
- Milestone 2: In the Thesis Proposal Report (TPR), the DPP is updated by the ESR according to the experiences gained during the first stage of the doctorate. The TPR is much more concrete and elaborated than the DPP and should be delivered no later than one month before the end of the first year.
- Milestone 3: In the Research Progress Report (RPR), the ESR updates the TPR according to the experiences gained during the second stage of the doctorate. The RPR includes a description of the main issues, early research results, and plan for the remaining work. The RPR should be delivered no later than one month before the end of the second year.
- Milestone 4: The Doctoral Thesis will be submitted at the end of the third year (M4).
The DPP, TPR, and RPR will all be accompanied by a Career Development Plan (CDP) that discusses the ESR's envisioned career opportunities and a roadmap to achieve them. After the submission of the Doctoral Thesis, the CDP is updated again to reflect achieved and new goals.
At the end of a secondment, a Secondment Report (SR) is prepared, describing not only the work and achieved goals, but also reflections on the experiences made and their influences on the ESR's future.
The DPP will be presented in a poster session in the first winter school, the TPR and RPR will be defended in front of the CPC and an external evaluator during the summer schools. A common evaluation of these documents was designed and includes the assessment of the potential contribution to innovation. If a report is not satisfactory, the ESR must resubmit within one month a new version that takes the CPC's feedback into account. If this version is not satisfactory, a "get back on track" procedure is activated, whereby the supervisors prepare a detailed action plan for the ESR's performance to become satisfactory after a three-month period. Subsequently, the CPC decides if the progress has been re-established. If the ESR does not accept this procedure or is unable to recover lost ground, he/she will be withdrawn from the programme. This decision does not necessarily entail any consequence with respect to the participation of the Candidate in local Doctorate programmes of the Home and Host universities.
The Doctoral Thesis will be evaluated with a common form in addition to local forms used by the Home and Host universities. It should contain material for at least 3 international peer-reviewed publications in indexed conferences or journals, of which 2 should be accepted for publication at the time of submission. After a unanimous recommendation by the CPC, it is submitted for evaluation by a Thesis Assessment Board (TAB) composed of members from at least four different institutions, containing: (1) at least one member from each of the Home and Host HEIs, and (2) at least one member external to the consortium, (3) the chair of the CPC (if local rules at the beneficiaries prevent this, e.g., due to a recent co-authorship between the supervisor and a potential TAB member, the local rules will be respected). The TAB will first state whether the thesis is satisfactory or not. If it is, a public, oral defence of the thesis will be held at the Home university in front of the TAB. Furthermore, the ESR will also present her/his work at a public seminar at the Host university. If the TAB considers the thesis is not satisfactory (which will occur rarely based on the partners' experience), it shall state whether the thesis may be resubmitted in a revised version within a deadline of at least three months. As stated in the Doctoral Candidate Agreement, ESRs who did not reach minimum criteria in the new version of the thesis will not be awarded the joint doctorate degree.
All other activities of the doctoral programme will also be assessed using a commonly agreed evaluation procedure. Secondments will be assessed using a common evaluation designed by the consortium. The ECTS acquired by an ESR in the programme will be recognised by the two institutions of the co-tutelle, independently of where they were acquired. Furthermore, the ESR's monitoring will be based on deliverables collected in a Candidate's Portfolio (CP) that contains, at least: (1) Doctoral Candidate Agreement, (2) DPP, (3) Transcripts of the courses, (4) Minutes of the periodic monitoring meetings, (5) TPR, (6) RPR, (7) Conference participations and other publications, (8) Secondment Reports. The CP will be at the disposal of the ESR, the CPC, and TAB.
In summary, the quality of the joint supervision results from:
- The joint doctoral process, which will maximise the ESRs' potential by a continuous monitoring.
- The expertise of the supervisors, who will ensure the pertinence of the research work with respect to the state-of-the-art.
- The beneficiaries, which are all highly recognised institutions and have worked together in European research and educational projects.
- The network of distinguished partner organisations.
- The quality assessment mechanisms for the programme.
- The demanding DEDS graduation requirements, which go beyond the standard criteria.
- The competitive selection procedure will lead to high quality research contributions.
- The mandatory publications that ensure that the ESRs will be independently evaluated, and which will improve the EHEA visibility and attractiveness.
Type of Diploma Awarded
At the end of the DEDS programme, provided that the ESR meets the academic requirements of the two universities of the co-tutelle allowing the Candidate to enter the doctoral procedure and to defend his/her doctorate, and after a successful defence of the Doctoral Thesis, the ESR will be awarded a Joint Doctoral Degree delivered by the two universities of the co-tutelle. The joint diploma is awarded by the academic authorities empowered to do so, on the basis of the conclusions of the appointed Thesis Assessment Board. The four universities awarding the joint doctoral degree under the co-tutelle model, bestowing the grades of:
- Doctorat en Sciences de l’Ingenieur (ULB)
- Doctor (UPC)
- Ph.D. in Computer Science (AAU)
- Ph.D. in Informatics and Telecommunications (UOA)
A Joint Europass Diploma Supplement will also be produced. It includes an overall description of the DEDS programme, a detailed description of the education and training programme followed by the Candidate, the information on the universities where the studies were conducted, the education system in the respective countries, and the partner organisations where the secondments were done.
In addition, the consortium will issue a Joint DEDS Certificate signed by all beneficiaries and a Europass Mobility Certificate for the secondments carried out.
Research Topics
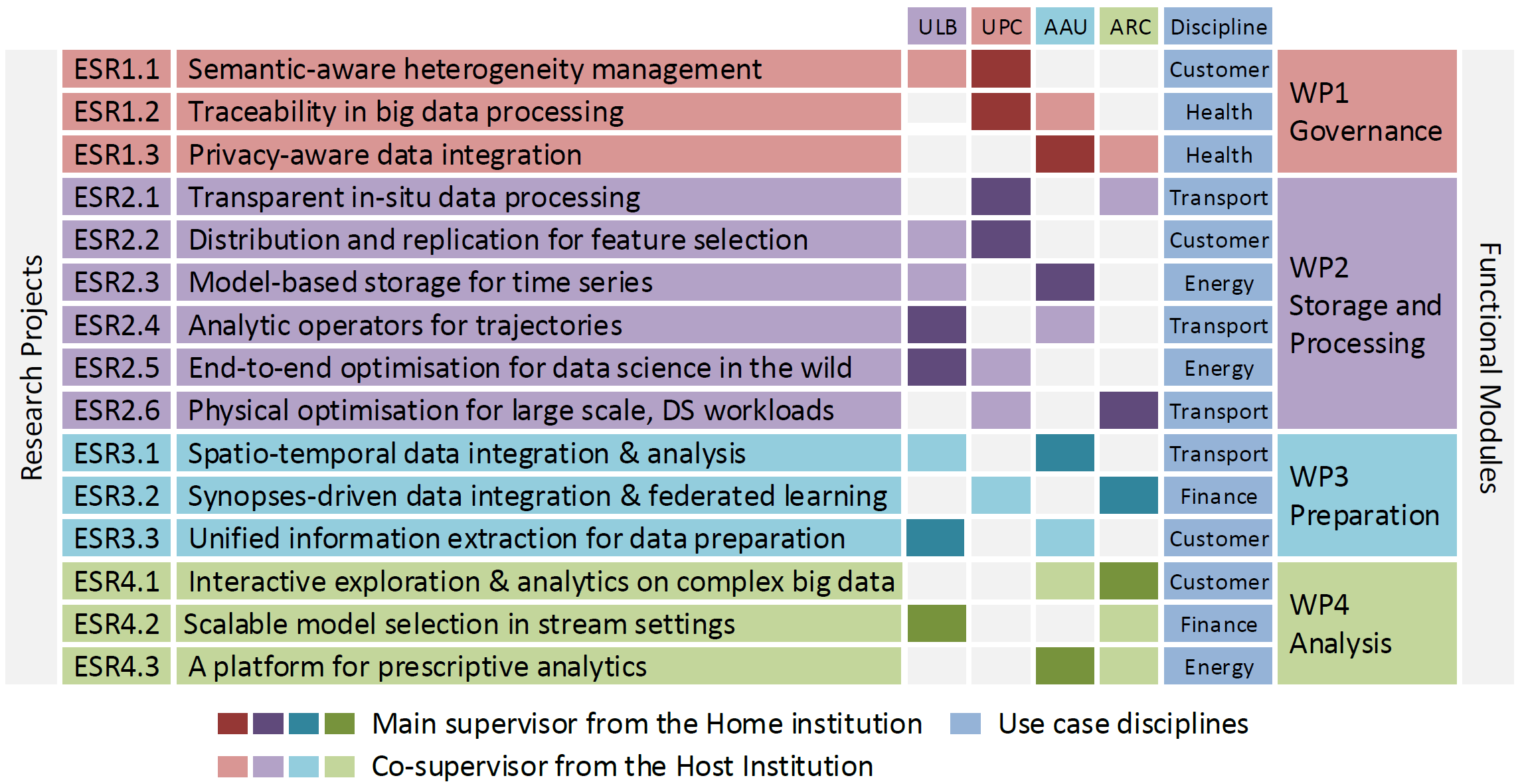
DEDS groups the planned contributions needed to unlock value from raw data into the following four functional modules, each addressing a different subset of research challenges:
- The Governance module considers privacy-aware mechanisms to manage and trace all data during the Data Science lifecycle, facilitating its automation.
- The Storage and Processing module investigates scalable mechanisms to efficiently store and process different kinds of data (e.g., temporal, geographical) both at rest (e.g., operational, historical) as well as in motion (e.g., real-time) benefiting from specific hardware accelerators.
- The Preparation module implements tools to effectively preprocess the data for analysis.
- The Analysis module extends traditional querying by devising data management mechanisms specifically tailored to analytical tasks.
The four modules collectively cover essential data engineering functionalities required along the Data Science lifecycle. Each module forms a work package (WP) and is composed of multiple Early Stage Researcher (ESR)) projects as shown in the following figure.
Research Positions
The following ESR positions are available, for details please click at the selected topic:
Governance
ESR 1.1: Semantic-aware heterogeneity management ESR 1.2: Traceability in big data processing ESR 1.3: Privacy-aware data integrationStorage and Processing
ESR 2.1: Transparent in-situ data processing ESR 2.2: Distribution and replication for feature selection ESR 2.3: Model-based storage for time series ESR 2.4: Analytic operators for trajectories ESR 2.5: End-to-end optimisation for data science in the wild ESR 2.6: Physical optimisation for large scale, DS workloadsPreparation
ESR 3.1: Spatio-temporal data integration & analysis ESR 3.2: Synopses-driven data integration & federated learning ESR 3.3: Unified information extraction for data preparationAnalysis
ESR 4.1: Interactive exploration & analytics on complex big data ESR 4.2: Scalable model selection in stream settings ESR 4.3: A platform for prescriptive analyticsContract and Salary
The ESR will receive a single, three-year employment contract issued by his/her Home Institution. The employment contract will provide by default social security coverage, holiday rights, parental leave rights, pension provision, healthcare insurance, and accident coverage at work. The contract guarantees that the ESR becomes a full member of the institution with the same rights as regular staff with the same position. This concerns, among others, working conditions, professional environment, access to the institutional resources, and participation (also by election) to various decision-making bodies.
During the whole period of enrolment in the DEDS programme, the ESR must not receive any scholarship or subvention by the European Commission within the framework of other Community programmes.
Mobility and Family Allowances
The ESR will receive a Mobility Allowance as a contribution to his/her mobility related expenses and a Family Allowance should he/she have family, regardless of whether the family will move with the Candidate or not. In this context, family is defined as persons linked to the Candidate by (i) marriage, or (ii) a relationship with equivalent status to a marriage recognised by the national or relevant regional legislation of the country where this relationship was formalised; or (iii) dependent children who are actually being maintained by the Candidate. The family status of a Candidate will be determined at the recruitment date and will not evolve during his/her participation in the DEDS programme. For ESRs employed at AAU, the Mobility and Family Allowances will be paid as part of the basic salary; not as a supplement.
Beneficiaries
Four top-class European institutions co-organize the DEDS programme:
University.
![]() ULB, with its 24,000 students and 5,000 staff, is one of the leading French-speaking universities in the world. It is a multicultural university with 33% of its students and 20% of its staff coming from abroad. The ULB has 13 faculties, schools and specialised institutes that cover all the disciplines, closely combining academic education and research. It offers almost 40 undergraduate programmes and 235 graduate programmes. It also partners 20 doctoral schools, with almost 1,600 doctorates in progress.
ULB, with its 24,000 students and 5,000 staff, is one of the leading French-speaking universities in the world. It is a multicultural university with 33% of its students and 20% of its staff coming from abroad. The ULB has 13 faculties, schools and specialised institutes that cover all the disciplines, closely combining academic education and research. It offers almost 40 undergraduate programmes and 235 graduate programmes. It also partners 20 doctoral schools, with almost 1,600 doctorates in progress.
With its four Nobel Prizes (three Scientific Nobel Prizes, one Peace Nobel Prize), one Fields Medal, one Abel Prize, three Wolf Prizes, two Marie Curie Awards, the ULB is also a major research university of worldwide standing in the academic community. Over the past few years, it has obtained 7 Starting Grants and 2 Advanced Grants from the European Research Council (ERC). Its Institute for European Studies is recognised as a "Jean Monnet European research centre" for its work on European integration. ULB currently participates in 120 international and European joint research projects. It participated in 76 EU FP6 projects and in 73 EU FP7 projects to date.
Collaboration with universities from around the world has been stepped up in both education and research. The ULB has 360 Erasmus partnerships, and 250 agreements with European and international universities. It coordinates one Erasmus Mundus Joint Doctorate and one Erasmus Mundus Joint Master and is partner in four Erasmus Mundus Action 2 programmes (India, China, Brazil, Japan-Corea). ULB launched UNICA, a network of 45 leading European universities that encompasses over a million students. It is also a founding member of the International Forum of Public Universities (IFPU). ULB has extensive experience in theses co-tutelle. For example, 13% of the Doctorate diplomas obtained in 2009–2010 were realised in co-tutelle. Further, in 2010–2011, 176 ongoing doctorate theses are realised in co-tutelle.
Departments. Resarch groups from two different departments participate in this proposal: Laboratory of Web and Information Technologies (WIT, prof. Zimányi in the CoDE Department) and the Machine Learning Group (MLG, prof. Bontempi, in the Computer Science Department).

The Department of Computer & Decision Engineering (CoDE) is composed of three laboratories of the Engineering Faculty: the Artificial and Swarm Intelligence Laboratory (IRIDIA), the Laboratory for Web and Information Technologies (WIT), and the Operational Research Laboratory (SMG). The aim of the department is to join the expertise of the three laboratories for realising innovative research, in particular in the area of business intelligence and data science. The department gathers 11 full-time professors, 50 researchers and PhD students, and 4 administrative/technical support staff. The department participated in numerous research projects, in particular, two ERC Grants, two FET projects (one as coordinator), one ARIADNA project of the European Space Agency and one Marie Curie Initial Training Network.
The Computer Science Department (DI) is composed of 5 laboratories of the Sciences Faculty: Algorithmic, Graphs and mathematical optimisation, Machine learning, Formal methods and verification, Quality and security of information systems. The department gathers 18 full-time professors, more than 60 researchers and PhD students, and 4 administrative/technical support staff. The department participated in numerous research projects, in particular, 1 ERC Grant, a Marie Curie Initial Training Network. and several projects funded by FNRS, Walloon Region and Brussels Region.
Groups.
 The Laboratory of Web and Information Technologies (WIT) has for years done cutting-edge research and development in the field of databases and business intelligence. WIT currently consists of 15 researchers (2 full-time professors, 3 postdocs, 10 PhD students ) and two administrative/technical support staff. The laboratory’s research focuses on data and information management with particular attention to: data warehousing and business intelligence, spatio-temporal and geographic data management, information extraction, and continuous query processing. WIT coorganises the "European Business Intelligence Summer School" (eBISS) since 2011125. Prof. Zimányi co-organised the Dagstuhl Seminar "Data Warehousing: Status Quo and Next Challenges", that took place in September 2011. Prof. Zimányi is Editor-in-Chief of the Journal on Data Semantics (JoDS) published by Springer.
The Laboratory of Web and Information Technologies (WIT) has for years done cutting-edge research and development in the field of databases and business intelligence. WIT currently consists of 15 researchers (2 full-time professors, 3 postdocs, 10 PhD students ) and two administrative/technical support staff. The laboratory’s research focuses on data and information management with particular attention to: data warehousing and business intelligence, spatio-temporal and geographic data management, information extraction, and continuous query processing. WIT coorganises the "European Business Intelligence Summer School" (eBISS) since 2011125. Prof. Zimányi co-organised the Dagstuhl Seminar "Data Warehousing: Status Quo and Next Challenges", that took place in September 2011. Prof. Zimányi is Editor-in-Chief of the Journal on Data Semantics (JoDS) published by Springer.
MLG currently consists of 18 researchers (4 full-time professors, 2 postdocs, 12 PhD students). The group is dedicated to theoretical and applied research in machine learning, covering research on scalable machine learning, computational modelling and statistics and their applications to problems of data mining, bioinformatics, simulation and time series prediction. Prof. Bontempi has been invited keynote speaker at numerous conferences and workshops, including “French German Summer School on Transfer Learning”, “Business Analytics in Finance and Industry”129, and the "Italy 2030" discussion at the European Parliament.
University.
![]() UPC is one of the distinguished universities in Spain and Europe. It is Campus of Excellence International (CEI)130 since the first round of the Ministry of Education in 2009 when it won recognition for the project Barcelona Knowledge Campus (BKC)131, presented in conjunction with the University of Barcelona. Over 35,000 students at UPC receive high quality education based on rigour, critical thinking, interdisciplinarity and an international outlook in the fields of engineering, architecture, and science. UPC’s academic itineraries and curricula have been designed to fulfil the needs of traditional and emerging production sectors. They are implemented in 69 graduate and undergraduate programmes, and 62 masters (22 taught entirely in English), that are structured in 23 schools, and have already been adapted to the European Higher Education Area. Besides this, there are 46 doctoral programmes, involving 3,000 students (28 cotutelle agreements have been signed only in 2011). With 13 Erasmus Mundus Masters, 5 Erasmus Mundus Doctorates and outstanding number of 95 international double-degree agreements with 44 universities worldwide, the UPC is able attract over 2,200 international students. In this context internationalisation is UPC’s main priority. UPC connects with other HEI and industry in seven international excellence networks (CESAER, CINDA, CLUSTER, EUA, TIME, UNITECH, and MAGALHAES).
UPC is one of the distinguished universities in Spain and Europe. It is Campus of Excellence International (CEI)130 since the first round of the Ministry of Education in 2009 when it won recognition for the project Barcelona Knowledge Campus (BKC)131, presented in conjunction with the University of Barcelona. Over 35,000 students at UPC receive high quality education based on rigour, critical thinking, interdisciplinarity and an international outlook in the fields of engineering, architecture, and science. UPC’s academic itineraries and curricula have been designed to fulfil the needs of traditional and emerging production sectors. They are implemented in 69 graduate and undergraduate programmes, and 62 masters (22 taught entirely in English), that are structured in 23 schools, and have already been adapted to the European Higher Education Area. Besides this, there are 46 doctoral programmes, involving 3,000 students (28 cotutelle agreements have been signed only in 2011). With 13 Erasmus Mundus Masters, 5 Erasmus Mundus Doctorates and outstanding number of 95 international double-degree agreements with 44 universities worldwide, the UPC is able attract over 2,200 international students. In this context internationalisation is UPC’s main priority. UPC connects with other HEI and industry in seven international excellence networks (CESAER, CINDA, CLUSTER, EUA, TIME, UNITECH, and MAGALHAES).
The UPC is a leading institution in innovation, research and technical development, worldwide recognised for its results in basic and applied research. 3,458 of its students are in educational cooperation agreements with companies. UPC's research portfolio covers the fields of Aerospace Engineering; Applied Sciences; Architecture, Urbanism and Building Construction; Audiovisual Communication and Media; Biosystems Engineering; Business Management and Organisation; Civil Engineering; Health Sciences and Technology; Industrial Engineering; Informatics Engineering; Naval, Maritime and Nautical Engineering; and Telecommunications Engineering. With its 2,780 professors and researchers, it develops an intense activity aimed at transferring technology and knowledge to private companies and to society. In 2011, the UPC collaborated with 2,680 companies, had 14 spin-offs, and 78 patent applications (33 of these internationally). In the same time, UPC’s 1,694 administration and services employees administered a total income of over 64 million Euro from R&D projects (54 European and 283 national) and technology transfer (506 agreements).
Department.
 The Engineering Department of Services and Information Systems is a new department created in 2009 that currently comprises about 20 full-time professors and 21 researchers and PhD students, who work collaboratively with a range of groups in Europe and Latin America, and are supported by the administration and IT staff of the LSIESSI Management Unit. It is structured in three research groups: Integrated Software, Service, Information and Data Engineering (inSSIDE), Information Modelling and Processing (MPI), which have been awarded Catalan government funding for the period 2018–2020 (under 2017SGR-1694, and 2017SGR-1749, respectively), and Technology and Humanism (STH) group created from the UNESCO Sustainability Chair and, most importantly, the interdepartmental doctoral programme of the same name, which is now coordinated by the UPC’s new University Research Institute for Sustainability Science and Technology. Their work is underpinned by a commitment to producing high-quality, tangible results through theoretical and technical research with clear practical applications. This is shown in the current four national research projects and one KA3 European project, as well as a Chair funded by Everis.
The Engineering Department of Services and Information Systems is a new department created in 2009 that currently comprises about 20 full-time professors and 21 researchers and PhD students, who work collaboratively with a range of groups in Europe and Latin America, and are supported by the administration and IT staff of the LSIESSI Management Unit. It is structured in three research groups: Integrated Software, Service, Information and Data Engineering (inSSIDE), Information Modelling and Processing (MPI), which have been awarded Catalan government funding for the period 2018–2020 (under 2017SGR-1694, and 2017SGR-1749, respectively), and Technology and Humanism (STH) group created from the UNESCO Sustainability Chair and, most importantly, the interdepartmental doctoral programme of the same name, which is now coordinated by the UPC’s new University Research Institute for Sustainability Science and Technology. Their work is underpinned by a commitment to producing high-quality, tangible results through theoretical and technical research with clear practical applications. This is shown in the current four national research projects and one KA3 European project, as well as a Chair funded by Everis.
Group.
 The main goal of the Integrated Software, Service, Information and Data Engineering (inSSIDE) research group is to explore aspects of software engineering and data management. Its researchers are particularly active in the fields of databases, data warehousing, conceptual modelling and ontologies, the semi-automatic generation of transformations between data schemas (relational and/or multidimensional), requierements engineering, software quality, software architecture, service-oriented computing, open source software, and empirical research. inSSIDE has a strong relationship with the “Conference on Advanced Information Systems Engineering (CAiSE)”, the head of the group being part of its programme board, bringing its organisation to Barcelona in 1997, and publishing papers regularly. The group currently consists of 10 full time professors, 4 postdocs, and 8 PhD students. Prof. Abelló is the local coordinator of the Erasmus Mundus PhD programme “Information Technologies for Business Intelligence - Doctoral College” (IT4BI-DC)133. He has been involved in many Programme Committees (being chair of DOLAP’08, and co-chair of MEDI2012 and DOLAP’18, and is member of the steering committee of “International Workshop of Data Warehousing and OLAP” (DOLAP) and “European Business Intelligence Summer School” (eBISS). Being member of the “Spanish Database Research Network”, he participated in 8 competitive research projects at the national level since 1998, currenly coordinating “Generation and Evolution of Smart APIs” (GENESIS).
The main goal of the Integrated Software, Service, Information and Data Engineering (inSSIDE) research group is to explore aspects of software engineering and data management. Its researchers are particularly active in the fields of databases, data warehousing, conceptual modelling and ontologies, the semi-automatic generation of transformations between data schemas (relational and/or multidimensional), requierements engineering, software quality, software architecture, service-oriented computing, open source software, and empirical research. inSSIDE has a strong relationship with the “Conference on Advanced Information Systems Engineering (CAiSE)”, the head of the group being part of its programme board, bringing its organisation to Barcelona in 1997, and publishing papers regularly. The group currently consists of 10 full time professors, 4 postdocs, and 8 PhD students. Prof. Abelló is the local coordinator of the Erasmus Mundus PhD programme “Information Technologies for Business Intelligence - Doctoral College” (IT4BI-DC)133. He has been involved in many Programme Committees (being chair of DOLAP’08, and co-chair of MEDI2012 and DOLAP’18, and is member of the steering committee of “International Workshop of Data Warehousing and OLAP” (DOLAP) and “European Business Intelligence Summer School” (eBISS). Being member of the “Spanish Database Research Network”, he participated in 8 competitive research projects at the national level since 1998, currenly coordinating “Generation and Evolution of Smart APIs” (GENESIS).
University.
![]() Aalborg Universitet stands out among older and more traditional Danish universities with its orientation on interdisciplinary problem-based work. Since its establishment in 1974, AAU has built a worldwide reputation for its problem-based learning model of problembased project work – also known as The Aalborg Model – and by extensive collaboration with the surrounding society. Within the fields of technical and natural sciences, social sciences, humanities, and health sciences, AAU currently educates more than 20,000 students, ranging from students at preparatory courses through doctoral-level candidates. These programmes aim to fulfil the requirements of both the private and the public sectors of the labour market. While AAU also provides elite programmes within a few selected areas (including data-intensive systems), it is taking steps to expand its reputation as an internationally recognised leading university within problem based learning. AAU’s programmes already attract approximately 15% international students, coming from different countries around the world. The international perspective is also reflected through the university’s active employment of international academic staff, the establishment of student exchange programmes and international research collaboration. AAU is characterised by combining a keen engagement in local, regional, and national issues with an active commitment to international collaboration. In 2015, AAU acquired 672 new external grants and administered external projects with a total turnover exceeding 85 million Euro. It has expanded its strong research areas ranging from basic research and applied research within all the academic fields represented at the university to world class research areas within selected fields. AAU has a strong focus on Information and Communications Technology (ICT), centred at the Technical Faculty of IT and Design. The strong focus makes AAU Denmark’s leading ICT university, attracting close to 39% of all new ICT students in Denmark. By further expanding its multidisciplinary research activities, increasing its collaboration across different research and knowledge areas, and strengthening its position as a network university, AAU has become one of the leading innovative universities in Europe. AAU has participated in 130 FP7 projects and currently participates in 57 H2020 projects.
Aalborg Universitet stands out among older and more traditional Danish universities with its orientation on interdisciplinary problem-based work. Since its establishment in 1974, AAU has built a worldwide reputation for its problem-based learning model of problembased project work – also known as The Aalborg Model – and by extensive collaboration with the surrounding society. Within the fields of technical and natural sciences, social sciences, humanities, and health sciences, AAU currently educates more than 20,000 students, ranging from students at preparatory courses through doctoral-level candidates. These programmes aim to fulfil the requirements of both the private and the public sectors of the labour market. While AAU also provides elite programmes within a few selected areas (including data-intensive systems), it is taking steps to expand its reputation as an internationally recognised leading university within problem based learning. AAU’s programmes already attract approximately 15% international students, coming from different countries around the world. The international perspective is also reflected through the university’s active employment of international academic staff, the establishment of student exchange programmes and international research collaboration. AAU is characterised by combining a keen engagement in local, regional, and national issues with an active commitment to international collaboration. In 2015, AAU acquired 672 new external grants and administered external projects with a total turnover exceeding 85 million Euro. It has expanded its strong research areas ranging from basic research and applied research within all the academic fields represented at the university to world class research areas within selected fields. AAU has a strong focus on Information and Communications Technology (ICT), centred at the Technical Faculty of IT and Design. The strong focus makes AAU Denmark’s leading ICT university, attracting close to 39% of all new ICT students in Denmark. By further expanding its multidisciplinary research activities, increasing its collaboration across different research and knowledge areas, and strengthening its position as a network university, AAU has become one of the leading innovative universities in Europe. AAU has participated in 130 FP7 projects and currently participates in 57 H2020 projects.
Department.
 The history of Computer Science at AAU goes back to 1976. In 1999 Computer Science became an independent department. The Department of Computer Science offers, apart from four programmes for Danishspeaking students, three international master’s programmes including one on Data Engineering. It also offers two elite education programmes within computer science: Data-Intensive Systems (headed by Prof. Pedersen) and Embedded Software Systems. The excellence of these programmes is recognised in the international benchmarking of Danish computer science in 2006: “AAU has developed programmes with a strong professional orientation [... that ...] make an important contribution to Danish computer science.” Currently, the department has 41 professors and 68 academic staff members, including more than 45 doctoral candidates, and educates around 1,000 students with 4% international. Along the line of the university, the department performs world-class international research within four main areas: database and programming technologies, distributed and embedded systems, machine intelligence, and information systems. The department has 7 ongoing or recent FP7 and H2020 projects.
The history of Computer Science at AAU goes back to 1976. In 1999 Computer Science became an independent department. The Department of Computer Science offers, apart from four programmes for Danishspeaking students, three international master’s programmes including one on Data Engineering. It also offers two elite education programmes within computer science: Data-Intensive Systems (headed by Prof. Pedersen) and Embedded Software Systems. The excellence of these programmes is recognised in the international benchmarking of Danish computer science in 2006: “AAU has developed programmes with a strong professional orientation [... that ...] make an important contribution to Danish computer science.” Currently, the department has 41 professors and 68 academic staff members, including more than 45 doctoral candidates, and educates around 1,000 students with 4% international. Along the line of the university, the department performs world-class international research within four main areas: database and programming technologies, distributed and embedded systems, machine intelligence, and information systems. The department has 7 ongoing or recent FP7 and H2020 projects.
Group.
 The Database, Programming and Web Technologies unit (DPW) at AAU is one of the three research units of the Department of Computer Science. In 2006, the group expanded its activities by establishing the Center for Data- Intensive Systems (Daisy) as a powerful platform for research and industry collaboration. Currently, DPW/Daisy, co-headed by Prof. Pedersen, consists of 16 professors, four post-doc researchers and more that 20 doctoral candidates. The overall topics of the group include Web data, graph data, RDF, business intelligence, spatio-temporal data, data streams, scalable and distributed systems, data mining, location-based mobile services, and programming languages and tools. The group has strong collaborations with national and international industry partners and universities (including ULB and UPC in the IT4BI-DC Erasmus Mundus programme). In a research evaluation, covering the period 2006–2010, the independent international evaluation committee concluded that DPT/Daisy is “[...] among the top-5 database groups in Europe, on level with institutions like ETH, and with an analogous significant reputation at world level.” For the period 2011–2015, the international evaluation committee concluded that “the unit is of excellent quality. The unit performs at world-class level.”
The Database, Programming and Web Technologies unit (DPW) at AAU is one of the three research units of the Department of Computer Science. In 2006, the group expanded its activities by establishing the Center for Data- Intensive Systems (Daisy) as a powerful platform for research and industry collaboration. Currently, DPW/Daisy, co-headed by Prof. Pedersen, consists of 16 professors, four post-doc researchers and more that 20 doctoral candidates. The overall topics of the group include Web data, graph data, RDF, business intelligence, spatio-temporal data, data streams, scalable and distributed systems, data mining, location-based mobile services, and programming languages and tools. The group has strong collaborations with national and international industry partners and universities (including ULB and UPC in the IT4BI-DC Erasmus Mundus programme). In a research evaluation, covering the period 2006–2010, the independent international evaluation committee concluded that DPT/Daisy is “[...] among the top-5 database groups in Europe, on level with institutions like ETH, and with an analogous significant reputation at world level.” For the period 2011–2015, the international evaluation committee concluded that “the unit is of excellent quality. The unit performs at world-class level.”
Research Center.
 The "Athena" Research and Innovation Centre in Information, Communication and Knowledge Technologies (ARC) is one of the leading research centers in Europe. It serves the full spectrum of the research lifecycle, starting from basic and applied research, continuing on to system & product building and infrastructure service provision, and ending with technology transfer and entrepreneurship. The fundamental role of ARC is to build knowledge and devise solutions and technologies for the digital society. Its value lies in the unique collection of skills and know-how of its researchers and professional staff and its national and international reputation. ARC comprises three institutes and five units. The institutes cover vibrant areas of digital technology and the units incubate know-how development activities that may lead to new major development directions. The institutes are: Institute for Language and Speech Processing (ILSP), the Industrial Systems Institute (ISI), and the Information Management Systems Institute (IMSI). The units are: Corallia - Hellenic technology cluster initiative, Space programmes (SPU), Robot perception and interaction (RPI), Environmental and networking technologies and applications (ENTA), and Pharma - Informatics.
The "Athena" Research and Innovation Centre in Information, Communication and Knowledge Technologies (ARC) is one of the leading research centers in Europe. It serves the full spectrum of the research lifecycle, starting from basic and applied research, continuing on to system & product building and infrastructure service provision, and ending with technology transfer and entrepreneurship. The fundamental role of ARC is to build knowledge and devise solutions and technologies for the digital society. Its value lies in the unique collection of skills and know-how of its researchers and professional staff and its national and international reputation. ARC comprises three institutes and five units. The institutes cover vibrant areas of digital technology and the units incubate know-how development activities that may lead to new major development directions. The institutes are: Institute for Language and Speech Processing (ILSP), the Industrial Systems Institute (ISI), and the Information Management Systems Institute (IMSI). The units are: Corallia - Hellenic technology cluster initiative, Space programmes (SPU), Robot perception and interaction (RPI), Environmental and networking technologies and applications (ENTA), and Pharma - Informatics.
Institute.
 ARC participates in the project through its Information Management Systems Institute (IMSI). Established in 2007, the Information Management Systems Institute (IMSI) is today one of Greece’s premier research centers in the areas of large-scale information systems and Big Data management. Over the past few years, the 100+ IMIS researchers have been very successful in attracting and implementing numerous cutting-edge research & development projects, at both the national and international level. IMSI has produced numerous, high quality scientific publications in these fields, and has a proven record of success in obtaining competitive funding from EU and national programmes. More than 90% of IMSI budget comes from competitive funding. The key personnel of IMSI have a long and pertinent experience in participating in and leading EU projects with an emphasis on topics for Big Data management, Cloud technologies, Open Data, and e-Infrastructures. IMSI has extensive research and innovation expertise in the areas of big data management and analytics, data modeling and integration, big data infrastructure, data exploration, user personalization, natural language processing, data privacy, linked data, data provenance, and more. IMSI provides knowledge management and information systems technologies for large-scale knowledge management, data-intensive applications, and for a wide range of digital resources and domains. It has successfully led the integration of manifold large-scale real-world information systems, daily offering their services to thousands of users, and has participated in many successful EU-funded Research & Innovation projects.
ARC participates in the project through its Information Management Systems Institute (IMSI). Established in 2007, the Information Management Systems Institute (IMSI) is today one of Greece’s premier research centers in the areas of large-scale information systems and Big Data management. Over the past few years, the 100+ IMIS researchers have been very successful in attracting and implementing numerous cutting-edge research & development projects, at both the national and international level. IMSI has produced numerous, high quality scientific publications in these fields, and has a proven record of success in obtaining competitive funding from EU and national programmes. More than 90% of IMSI budget comes from competitive funding. The key personnel of IMSI have a long and pertinent experience in participating in and leading EU projects with an emphasis on topics for Big Data management, Cloud technologies, Open Data, and e-Infrastructures. IMSI has extensive research and innovation expertise in the areas of big data management and analytics, data modeling and integration, big data infrastructure, data exploration, user personalization, natural language processing, data privacy, linked data, data provenance, and more. IMSI provides knowledge management and information systems technologies for large-scale knowledge management, data-intensive applications, and for a wide range of digital resources and domains. It has successfully led the integration of manifold large-scale real-world information systems, daily offering their services to thousands of users, and has participated in many successful EU-funded Research & Innovation projects.
Supervisors
The DEDS supervisory team are world-class experts in the domains of data management and analytics, bringing at the same time a complementary expertise in relevant disciplines as well. The DEDS supervisors have demonstrated both supervision experience and a record of academic performance at a high level of excellence. They have extensive experience in supervising in total more than 145 PhD students, many of which under double/joint degree agreements. In the last five years, they have published 440+ articles in top journals and conferences, and scientific books.Prof. Esteban Zimányi.  Coordinator of the IT4BI, IT4BI-DC, and BDMA EM programmes. Publications: 16 co-authored and co-edited books, 18 book chapters, 19 journal papers, 82 conference papers. H-index: 34. Projects: 24 research projects (incl. 5 EM, 1 FP5). PhD supervision: 15 graduated, 10 ongoing. Expertise: data warehouses and OLAP, spatio-temporal data management, semantic web. Role: Programme Coordinator,
supervision of ESR2.3, ESR2.4, ESR2.5, and ESR3.1.
Coordinator of the IT4BI, IT4BI-DC, and BDMA EM programmes. Publications: 16 co-authored and co-edited books, 18 book chapters, 19 journal papers, 82 conference papers. H-index: 34. Projects: 24 research projects (incl. 5 EM, 1 FP5). PhD supervision: 15 graduated, 10 ongoing. Expertise: data warehouses and OLAP, spatio-temporal data management, semantic web. Role: Programme Coordinator,
supervision of ESR2.3, ESR2.4, ESR2.5, and ESR3.1.
Prof. Gianluca Bontempi.  Publications: 3 co-authored and co-edited books, 11 book chapters, 90 journal papers, 97 conference papers. Best paper awards at DSAA 2017. H-index: 52. Projects: 6 research projects. PhD supervision: 12 graduated, 3 ongoing. Expertise: scalable ML, big data science, forecasting, modeling, simulation. Role: Supervision of ESR2.2, ESR3.3, and ESR4.2.
Publications: 3 co-authored and co-edited books, 11 book chapters, 90 journal papers, 97 conference papers. Best paper awards at DSAA 2017. H-index: 52. Projects: 6 research projects. PhD supervision: 12 graduated, 3 ongoing. Expertise: scalable ML, big data science, forecasting, modeling, simulation. Role: Supervision of ESR2.2, ESR3.3, and ESR4.2.
Prof. Dimitris Sacharidis.  Publications: 3 book chapters, 13 journal papers, 57 conference papers. H-index: 19. Projects: 5 research projects. PhD Supervision: 5 students co-supervised. Expertise: data science, big data analytics, recommender systems, and machine learning. Role: Supervision of ESR1.1, ESR2.5, ESR3.3.
Publications: 3 book chapters, 13 journal papers, 57 conference papers. H-index: 19. Projects: 5 research projects. PhD Supervision: 5 students co-supervised. Expertise: data science, big data analytics, recommender systems, and machine learning. Role: Supervision of ESR1.1, ESR2.5, ESR3.3.
Prof. Mahmoud Sakr.  Publications: 1 book chapter, 32 published papers, H-index: 11. Projects: 8 research projects (incl. 2 EM, 2 ITN, 2 Horizon). PhD supervision: 6 ongoing. Expertise: data management, co-founder of the MobilityDB opensource, co-chair of the OGC Moving Feature Standards Working Group. Role: ULB Coordinator,
supervision of ESR2.4 and ESR3.1.
Publications: 1 book chapter, 32 published papers, H-index: 11. Projects: 8 research projects (incl. 2 EM, 2 ITN, 2 Horizon). PhD supervision: 6 ongoing. Expertise: data management, co-founder of the MobilityDB opensource, co-chair of the OGC Moving Feature Standards Working Group. Role: ULB Coordinator,
supervision of ESR2.4 and ESR3.1.
Prof. Alberto Abelló.  Local coordinator of T4BI-DC EM programme. Publications: 27 journal papers, 70 conference papers, 10 book chapters, 6 edited books and journals. H-index: 26. Projects: 12 research projects (incl. 3 EM, 1 H2020), 8 industrial projects (incl. HP Labs, SAP, WHO, Zurich IG). PhD supervision: 8 graduated, 3 ongoing. Expertise: big data management, data-intensive flows, query optimization, metadata management. Role: Local Programme Coordinator at UPC,
supervision of ESR1.2, ESR2.2, ESR2.5 and ESR2.6.
Local coordinator of T4BI-DC EM programme. Publications: 27 journal papers, 70 conference papers, 10 book chapters, 6 edited books and journals. H-index: 26. Projects: 12 research projects (incl. 3 EM, 1 H2020), 8 industrial projects (incl. HP Labs, SAP, WHO, Zurich IG). PhD supervision: 8 graduated, 3 ongoing. Expertise: big data management, data-intensive flows, query optimization, metadata management. Role: Local Programme Coordinator at UPC,
supervision of ESR1.2, ESR2.2, ESR2.5 and ESR2.6.
Prof. Oscar Romero.  Local coordinator of the BDMA EM programme and the Data Science master at the Faculty of Informatics of UPC. Publications: 4 book chapters, 20 journal papers, 50 conference papers. H-index: 19. Projects: 10 research projects (incl. 3 EM, 1 H2020), 7 industrial projects (incl. HP Labs, SAP, WHO, Zurich IG). PhD supervision: 4 graduated, 4 ongoing. Expertise: big data management, data integration, semantic web, data-intensive flows, metadata management, automatic user assistance. Role:
Supervision of ESR1.1, ESR2.1 and ESR3.2.
Local coordinator of the BDMA EM programme and the Data Science master at the Faculty of Informatics of UPC. Publications: 4 book chapters, 20 journal papers, 50 conference papers. H-index: 19. Projects: 10 research projects (incl. 3 EM, 1 H2020), 7 industrial projects (incl. HP Labs, SAP, WHO, Zurich IG). PhD supervision: 4 graduated, 4 ongoing. Expertise: big data management, data integration, semantic web, data-intensive flows, metadata management, automatic user assistance. Role:
Supervision of ESR1.1, ESR2.1 and ESR3.2.
Prof. Torben Bach Pedersen.  ACM Distinguished Scientist. Publications: 11 co-authored and co-edited books, 15 book chapters, 44 journal papers, 139 conference papers. H-index: 45. Projects: 22 research projects (incl. 1 EM, 2 H2020, 2 FP7, 1 FP6), 10 Danish strategic projects with industrial partners (including SAP, IBM Ireland, TARGIT, Lyngsoe, SAS, IATA). 2 software patents. PhD supervision: 20 graduated, 9 ongoing. Expertise: big data analytics, business intelligence, multidimensional databases, OLAP, data mining. Role: Local Programme Coordinator at AAU, supervision of ESR4.1 and ESR4.3.
ACM Distinguished Scientist. Publications: 11 co-authored and co-edited books, 15 book chapters, 44 journal papers, 139 conference papers. H-index: 45. Projects: 22 research projects (incl. 1 EM, 2 H2020, 2 FP7, 1 FP6), 10 Danish strategic projects with industrial partners (including SAP, IBM Ireland, TARGIT, Lyngsoe, SAS, IATA). 2 software patents. PhD supervision: 20 graduated, 9 ongoing. Expertise: big data analytics, business intelligence, multidimensional databases, OLAP, data mining. Role: Local Programme Coordinator at AAU, supervision of ESR4.1 and ESR4.3.
Prof. Katja Hose.  Publications: 1 co-authored/co-edited book, 1 book chapter, 18 journal papers, 74 conference papers. Best student paper award at WWW 2013, best demo award at WWW 2017, best poster award at ESWC 2018. H-index: 20. Projects: 5 research projects. PhD supervision: 3 graduated, 5 ongoing. Expertise: distributed query processing and optimisation, data integration, indexing, Semantic Web and Linked Open Data. Role: Equal opportunities commissioner (EOC), supervision of ESR1.2, ESR1.3, and ESR3.3.
Publications: 1 co-authored/co-edited book, 1 book chapter, 18 journal papers, 74 conference papers. Best student paper award at WWW 2013, best demo award at WWW 2017, best poster award at ESWC 2018. H-index: 20. Projects: 5 research projects. PhD supervision: 3 graduated, 5 ongoing. Expertise: distributed query processing and optimisation, data integration, indexing, Semantic Web and Linked Open Data. Role: Equal opportunities commissioner (EOC), supervision of ESR1.2, ESR1.3, and ESR3.3.
Prof. Christian Thomsen .  Publications: 1 co-authored book, 9 journal papers, 24 conference papers. H-index: 15. Projects: 1 research project. PhD supervision: 2 graduated, 5 ongoing. Expertise: data warehousing, OLAP, ETL, big data management, data-intensive flows. Role:
Supervision of ESR2.3.
Publications: 1 co-authored book, 9 journal papers, 24 conference papers. H-index: 15. Projects: 1 research project. PhD supervision: 2 graduated, 5 ongoing. Expertise: data warehousing, OLAP, ETL, big data management, data-intensive flows. Role:
Supervision of ESR2.3.
Prof. Kristian Torp .  Publications: 1 book chapters, 5 journal papers , 30 conference papers. H-index: 13. Projects: 5 research projects (2 FP7, 2 H2020, 1 InterReg). PhD supervision: 2 graduated, 1 ongoing. Expertise: data management, GPS data, fuel data, spatio-temporal dataRole:
Supervision of ESR2.4 and ESR3.1.
Publications: 1 book chapters, 5 journal papers , 30 conference papers. H-index: 13. Projects: 5 research projects (2 FP7, 2 H2020, 1 InterReg). PhD supervision: 2 graduated, 1 ongoing. Expertise: data management, GPS data, fuel data, spatio-temporal dataRole:
Supervision of ESR2.4 and ESR3.1.
Prof. Minos Garofalakis .  ACM/IEEE Fellow. Publications: 2 co-authored and co-edited books, 7 book chapters, 57 journal papers, 95 conference papers. H-index: 63. Projects: 7 research projects. 29 patents. PhD supervision: 1 graduated, 1 ongoing. Expertise: big data analytics, largescale machine learning, database systems, centralized/distributed data streams, data synopses and approximate query processing, uncertain databases, secure/private data analytics. Role: Supervision of ESR1.3, ESR3.2, and ESR4.2.
ACM/IEEE Fellow. Publications: 2 co-authored and co-edited books, 7 book chapters, 57 journal papers, 95 conference papers. H-index: 63. Projects: 7 research projects. 29 patents. PhD supervision: 1 graduated, 1 ongoing. Expertise: big data analytics, largescale machine learning, database systems, centralized/distributed data streams, data synopses and approximate query processing, uncertain databases, secure/private data analytics. Role: Supervision of ESR1.3, ESR3.2, and ESR4.2.
Prof. Yannis Ioannidis .  ACM/IEEE Fellow, member of Academia Europaea, recipient of ACM SIGMOD Contributions Award, VLDB 10-year best paper award.Publications: 8 co-edited proceedings-based books, 9 book chapters, 71 journal papers, 150 conference papers. H-index: 60. Projects: 40+ research projects. PhD supervision: 14 graduated, 8 ongoing. Expertise: data science, data and text analytics, scalable data processing, recommender systems and personalization. Role:
Supervision of ESR4.1 and ESR4.3.
ACM/IEEE Fellow, member of Academia Europaea, recipient of ACM SIGMOD Contributions Award, VLDB 10-year best paper award.Publications: 8 co-edited proceedings-based books, 9 book chapters, 71 journal papers, 150 conference papers. H-index: 60. Projects: 40+ research projects. PhD supervision: 14 graduated, 8 ongoing. Expertise: data science, data and text analytics, scalable data processing, recommender systems and personalization. Role:
Supervision of ESR4.1 and ESR4.3.
Dr. Alkis Simitsis.  IEEE senior member. Publications: 2 co-authored and co-edited books, 9 book chapters, 17 journal papers, 76 Conference papers. H-index: 41. Projects: 15+ industrial projects (with IBM, HP, HPE, MicroFocus). 36 patents. PhD supervision: 2 thesis committees, 8 mentored. Expertise: scalable big data infrastructure, data-intensive analytics, real-time business intelligence, massively parallel processing, cloud computing. Role: Local Programme Coordinator at ARC,
supervision of ESR2.1 and ESR2.6.
IEEE senior member. Publications: 2 co-authored and co-edited books, 9 book chapters, 17 journal papers, 76 Conference papers. H-index: 41. Projects: 15+ industrial projects (with IBM, HP, HPE, MicroFocus). 36 patents. PhD supervision: 2 thesis committees, 8 mentored. Expertise: scalable big data infrastructure, data-intensive analytics, real-time business intelligence, massively parallel processing, cloud computing. Role: Local Programme Coordinator at ARC,
supervision of ESR2.1 and ESR2.6.
Partner Organisations
ESRs will have the opportunity to do part of their research work at associated partners comprising prominent research and industry organizations.The partner organisations, nine of which have research departments, were selected to bring additional expertise to the consortium to support the beneficiaries in the training of students at the forefront of research and innovation. As domain experts and innovation leaders, they have unique insights into, and experience with, the specific problems of the data value creation lifecycle in their domain. Hence, they provide crucial use cases and datasets in which the proposed research can be grounded or validated. As the figure below illustrates, these use cases collectively cover a wide range of sectors and disciplines, including Energy (CERN, SG), Health (AUH, WHO), Finance (SPR, WOL), Transport (BSC, EUC, FDK, MT), and Customer Relationship and Support (DGT, EUN, ORA, RM). Besides their role of use case providers, as open source platform leaders, CERN and RM will also help on the integration of the research.
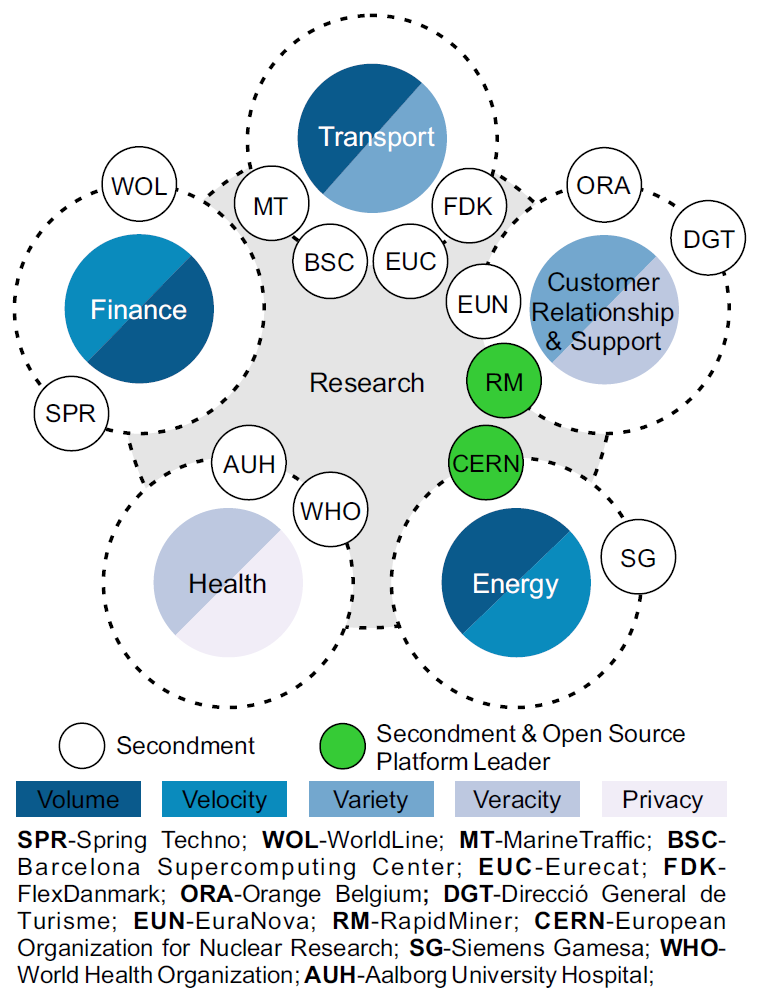
A list of the partner organization follows:
Higher Education Institutions
- National and Kapodistrian University of Athens (UOA), EL - Degree Awarding Institute for ARC
- Technische Universitat Dresden (TUD), DE - Advisory board
Academic Network
- T.I.M.E. Association, FR - Communication and dissemination, quality assessment, advisory board
Research Institutes
- Barcelona Supercomputing Center (BSC), ES - ESR secondment, original research
- European Organization for Nuclear Research (CERN), CH - ESR secondment, original research, incubator
- Eurecat (EUC), ES - ESR secondment, original research
Industrial Companies
- EURA NOVA (EUN), BE - ESR secondment, original research
- FlexDanmark (FDK), DK - ESR secondment, original research
- Marine Traffic (MT), EL - ESR secondment, original research
- Orange Belgium (ORA), BE - ESR secondment, original research
- RapidMiner (RM), DE - ESR secondment, original research
- Siemens Gamesa Renewable Energy A/S (SG), DK - ESR secondment, original research
- Spring Techno (SPR), DE - ESR secondment, original research
- Worldline (WOL), FR - ESR secondment, original research
Public Organisations
- Aalborg University Hospital, Department of Haematology (AUH), DK - ESR secondment, original research
- Direccio General de Turisme, Catalan Government (DGT), ES - ESR secondment, original research
- World Health Organization, Neglected Tropical Diseases (WHO), CH - ESR secondment, original research









How to Apply
To apply for the programme, please fill in the application form at the following URL:
Application form: https://deds.ulb.ac.be/emundus/
Application manual: Before applying please, read carefully the Application Manual that describes in detail the application procedure and requirements. It covers the most frequent questions.
Important Dates
Applications will be accepted until all positions are filled. We encourage excellent candidates to apply early to maximize chances that their first ESR choices will still be available.
Eligibility Criteria
Applications must abide by the following minimum eligibility criteria (EC):
- EC1: The Candidate must have been awarded the equivalent of 300 ECTS from his/her Bachelor and Master's degrees (of which, at least 60 of those ECTS must correspond to the Master's degree) with a major in computer science, from an accredited university listed in the World Higher Education Database (WHED) or included in the following university rankings: (a) The Times Higher Education World University Rankings, (b) Academic Ranking of World Universities, or (c) QS World University Rankings.
- EC2: The Candidate must be able to demonstrate proficiency in English by means of:
(a) Either an internationally recognised test equivalent to level C1 in the Common European Framework of Reference for Languages (CEFR). These tests include, e.g., Cambridge English First A, IELTS (academic) 7.0, TOEFL (paper based) 590, TOEFL (computer based) 243, TOEFL (Internet based), etc.
(b) Or, a document issued by the university awarding his/her Bachelor or Master's degree certifying that its tuition language was English.
- EC3: The Candidate must be, at the date of recruitment, in the first four years (full-time equivalent research experience) of his/her research career and has not been awarded a doctoral degree. The full-time equivalent research experience is measured from the date when the Candidate obtained the degree entitling him/her to embark on a doctorate, either in the country in which the degree was obtained or in the country in which the Candidate is recruited, even if a doctorate was never started or envisaged. Applicants who were awarded the degree entitling him/her to embark on a doctorate in a period longer than the stated, must describe in the cover letter the activities undertaken during this period. These activities cannot be research-oriented.
- EC4: The Candidate must not have resided or carried out his/her main activity (work, studies, etc.) in the country of the Home Institution for more than 12 months in the 3 years immediately before the recruitment date. Compulsory national service, short stays such as holidays, and time spent as part of a procedure for obtaining refugee status under the Geneva Convention are not taken into account.
Selection Procedure
Eligible applications will be scored according to the following selection criteria (SC):
- SC1: Domain of the bachelor and master 15%
- SC2: Normalised academic results 40%
- SC3: Research experience 15%
- SC4: Professional experience 10%
- SC5: Recommendation letters 10%
- SC6: CV, research proposal, and motivation 10%
Criteria SC1–SC4 correspond to a score automatically calculated, while criteria SC5 and SC6 will be manually scored by the experts of the Selection and Evaluation Committee (SEC). A final score will be calculated for each applicant, and a first ranking automatically produced, which will help the SEC do a first pre-selection.
Two knockout rounds of interviews will be performed. The first one focusing on transversal skills, and the second on technical background, including the discussion of a research paper.
A main and a reserve list will be produced (with a third interview for borderline candidates) and when approved by the relevant Home and Host universities, the Committee will notify the applicants of the result of the selection process. Non-granted candidates may appeal through a complaint letter.
Selected applicants will receive an official letter of acceptance, the Candidate Agreement and practical information about the programme. After confirmation from the candidate who will return the Candidate Agreement signed, the hiring and registration process will start at the corresponding beneficiaries.
Training Events
To complement the local training at the Home/Host universities, the consortium will benefit from DEDS's multidisciplinary nature and organise training events specifically targeted at the ESRs' needs as listed below.
- Winter School on "Ethical and Legal Aspects of Data"
Organizer: ARC
School dates: April 4 - April 8, 2022
School website: [url]
- Summer School on "Big Data Analytics and Management"
Organizer: ULB, month 17
Main contributors: ULB (Spatial data analytics), RM (Data science in industry), CERN (Data Science in research), TUD (Scalable Data Science Systems)
- Winter School on "Entrepreneurship and Innovation"
Organizer: AAU, month 24
Main contributors: AAU (IPR, spin-off creation), EUN (Research-driven innovation), BSC (Technology transfer), CERN (Entrepreneurship), EUC (Data Science innovation)
- Summer School on "Applied Statistics"
Organizer: UPC, month 29
Main contributors: UPC (Modern statistical tools and methods), MT (Applied Machine Learning), WOL (Timeseries forecasting)
- Final Conference on "Data Engineering for Data Science Innovation"
Organizer: ULB, month 41
Main contributors: All
The winter schools are devoted to the development of transferable skills. The first one brings knowledge and skills from the ethical and legal domains, which are crucial for data scientists. The second winter school provides ESRs with knowledge about how to commercialize research results, first focusing on entrepreneurship and exploring how to turn research into innovations and new startups, and then focusing on Intellectual Property Rights and give an understanding of the importance of using patents.
The summer schools are devoted to core scientific skills and explore emerging perspectives in Data Science. The first one provides ESRs with deep understanding of the relationship between data analytics and the management of Big Data. The second one reinforces students with knowledge and experience of applied statistics.
The final conference disseminates the results of the project to both industry and academic sectors.
Both academic and non-academic partners are involved in all schools and the final conference. In addition to offering training opportunities, the winter and summer schools also act as mechanisms for the ESRs to present and discuss their research and training, and get feedback from all members of the consortium (both academic and non-academic) as well as external experts, thus being collectively monitored and externally evaluated.
Under construction...
Useful Documents, Publications, and Code repositories
Promotional material: Documents to advertise DEDS' activities (posters, leaflets, etc.)

Poster
[pdf] 918KB
[png] 568KB
![[png]](docs/promotion/deds-poster-2.png){kind=link}

CFP
[pdf] 192KB
[txt] 4KB

Promo from UPC
[pdf] 1.6MB
Publications:
- Compressing High-Frequency Time Series Through Multiple Models and Stealing from Residuals
Abduvoris Abduvakhobov, Søren Kejser Jensen, Christian Thomsen, Torben Bach Pedersen
In IEEEE ICDE, 2026. - CAPS: Cost-Aware ML Pipeline Selection
Antonios Kontaxakis, Dimitris Sacharidis, Alkis Simitsis, Alberto Abelló, Sergi Nadal
In VLDB, 2026. - Scalable Model-Based Management of Massive High Frequency Wind Turbine Data with ModelarDB
Abduvoris Abduvakhobov, Søren Kejser Jensen, Torben Bach Pedersen, Christian Thomsen
In VLDB, 2025. - A Framework for Automated Junction Analysis
Rodrigo Sasse David, Kristian Torp, Mahmoud Sakr, Esteban Zimanyi
In ACM SIGSPATIAL, 2025. - Hyppo: Efficient Discovery and Execution of Data Science Pipelines in Collaborative Environments
Antonios Kontaxakis, Dimitris Sacharidis, Alkis Simitsis, Alberto Abelló, Sergi Nadal
In EDBT, 2025. - Comparative Analysis of Indexing Techniques for Table Search in Data Lakes
IbraheemTaha, Matteo Lissandrini, Alkis Simitsis, Yannis Ioannidis
In IJSC, 2025. - On many-objective feature selection and the need for interpretability
Uchechukwu Fortune Njoku, Alberto Abelló Gamazo, Besim Bilalli, Gianluca Bontempi
In Expert Systems with Applications (267), 2025. - Effective Ship Trajectory Imputation with Multiple Coastal Cameras
Song Wu, Kristian Torp, Alexandros Troupiotis-Kapeliaris, Dimitris Zissis, Esteban Zimányi, Mahmoud Sakr
In IEEE MDM, 2025. - HAIDES: Adaptive Approximation of Inference Queries over Unstructured Data
Christos Papadopoulos, Alkis Simitsis, Torben Bach Pedersen
In IEEE ICDE, 2025. - Evaluating Quality of Disparate Data Sources: A Discord-Driven Approach
Yeasmin Ara Akter, Alberto Abelló, Petar Jovanovic, Tomer Sagi, Katja Hose
In ADBIS, 2025. - Towards fair machine learning using Many-Objective Feature Selection
Uchechukwu Fortune Njoku, Alberto Abelló Gamazo, Besim Bilalli, Gianluca Bontempi
In Applied Soft Computing (181), 2025. - Document Attribution in RAG
Ikhtiyor Nematov, Dimitris Sacharidis, Katja Hose, Tomer Sagi
In AIMLAI (with ECML/PKDD), 2025. - Pasteur: Scaling Privacy-aware Data Synthesis
Antheas Kapenekakis, Daniele Dell'Aglio, Martin Bøgsted, Minos Garofalakis, Katja Hose
In ADBIS, 2025. - Quality of Hybrid GNSS Sampling
Rodrigo Sasse David, Kristian Torp, Anders Zinck Justesen, Mahmoud Sakr, Esteban Zimányi
In IEEE MDM, 2025. - A Study on Efficient Indexing for Table Search in Data Lakes
IbraheemTaha, Matteo Lissandrini, Alkis Simitsis, Yannis Ioannidis
In IEEE ICSC, 2024. - Performance Analysis of Distributed GPU-Accelerated Task-Based Workflows
Marcos N. L. Carvalho, Anna Queralt, Oscar Romero, Alkis Simitsis, Cristian Tatu, Rosa M. Badia
In EDBT, 2024. - Workload Placement on Heterogeneous CPU-GPU Systems
Marcos N. L. Carvalho, Alkis Simitsis, Anna Queralt, Oscar Romero
In VLDB, 2024. - Mitigating Data Sparsity in Integrated Data through Text Conceptualization
Md Ataur Rahman, Sergi Nadal, Oscar Romero, Dimitris Sacharidis
In IEEE ICDE, 2024. - Mobility Data Science: Perspectives and Challenges
Mohamed F. Mokbel, Mahmoud Attia Sakr, Li Xiong, Andreas Züfle, Jussara M. Almeida, Taylor Anderson, Walid G. Aref, Gennady L. Andrienko, Natalia V. Andrienko, Yang Cao, Sanjay Chawla, Reynold Cheng, Panos K. Chrysanthis, Xiqi Fei, Gabriel Ghinita, Anita Graser, Dimitrios Gunopulos, Christian S. Jensen, Joon-Seok Kim, Kyoung-Sook Kim, Peer Kröger, John Krumm, Johannes Lauer, Amr Magdy, Mario A. Nascimento, Siva Ravada, Matthias Renz, Dimitris Sacharidis, Flora D. Salim, Mohamed Sarwat, Maxime Schoemans, Cyrus Shahabi, Bettina Speckmann, Egemen Tanin, Xu Teng, Yannis Theodoridis, Kristian Torp, Goce Trajcevski, Marc J. van Kreveld, Carola Wenk, Martin Werner, Raymond Chi-Wing Wong, Song Wu, Jianqiu Xu, Moustafa Youssef, Demetris Zeinalipour, Mengxuan Zhang, Esteban Zimányi
In ACM Trans. Spatial Alg. Syst. 10(2), 2024. - AIDE: Antithetical, Intent-based, and Diverse Example-Based Explanations
Ikhtiyor Nematov, Dimitris Sacharidis, Katja Hose, Tomer Sagi
In AAAI/ACM AIES, 2024. - The Susceptibility of Example-Based Explainability Methods to Class Outliers
Ikhtiyor Nematov, Dimitris Sacharidis, Katja Hose, Tomer Sagi
In AIMLAI (with ECML/PKDD), 2024. - HYPPO - Using Equivalences to Optimize Pipelines in Exploratory Machine Learning
Antonios Kontaxakis, Dimitris Sacharidis, Alkis Simitsis, Alberto Abelló, Sergi Nadal
In IEEE ICDE, 2024. - Uncertainty-Aware Ship Location Estimation using Multiple Cameras in Coastal Areas
Song Wu, Alexandros Troupiotis-Kapeliaris, Dimitris Zissis, Kristian Torp, Esteban Zimányi, Mahmoud Sakr
In IEEE MDM, 2024. - Finding Relevant Information in Big Datasets with ML.
Uchechukwu Fortune Njoku, Alberto Abelló Gamazo, Besim Bilalli, Gianluca Bontempi
In EDBT, 2024. - A data-science pipeline to enable the Interpretability of Many-Objective Feature Selection
Uchechukwu Fortune Njoku, Alberto Abelló Gamazo, Besim Bilalli, Gianluca Bontempi
In DOLAP (with EDBT/ICDT), 2024. - Intent-aware Example-based Explainability
Ikhtiyor Nematov, Dimitris Sacharidis, Katja Hose, Tomer Sagi
In AAAI/ACM AIES, 2024. - Synthesizing Accurate Relational Data under Differential Privacy
Antheas Kapenekakis, Daniele Dell’Aglio, Charles Vesteghem, Laurids Poulsen, Martin Bøgsted, Minos Garofalakis
In IEEE Big Data Conference, 2024. - Assessing adversarial attacks in real-world fraud detection
Daniele Lunghi, Alkis Simitsis, Gianluca Bontempi
In IEEE ICWS, 2024. - And synopses for all: A synopses data engine for extreme scale analytics-as-a-service
Antonios Kontaxakis, Nikos Giatrakos, Dimitris Sacharidis, Antonios Deligiannakis
In Information Systems (116), 2023. - Wrapper Methods for Multi-Objective Feature Selection
Uchechukwu Fortune Njoku, Alberto Abelló Gamazo, Besim Bilalli, Gianluca Bontempi
In EDBT, 2023. - Evaluation of Vessel CO2 Emissions Methods Using AIS Trajectories
Song Wu, Kristian Torp, Mahmoud Sakr, Esteban Zimanyi
In SSTD, 2023. - Adversarial Learning in Real-World Fraud Detection: Challenges and Perspectives
Daniele Lunghi, Alkis Simitsis, Olivier Caelen, Gianluca Bontempi
In ACM Data Economy (with ACM SIGMOD), 2023. - Roundabouts and the Energy Efficiency of Electrical Vehicles
Rodrigo Sasse David, Kristian Torp, Mahmoud Sakr, Esteban Zimanyi
In IWCTS (with ACM SIGSPATIAL), 2023. - An adversary model of fraudsters’ behavior to improve oversampling in credit card fraud detection
Daniele Lunghi, GM Paldino, Oliver Caelen, Gianluca Bontempi
In IEEE Access (11), 2023. - Impact of filter feature selection on classification: an empirical study
Uchechukwu Fortune Njoku, Alberto Abelló Gamazo, Besim Bilalli, Gianluca Bontempi
In DOLAP (with EDBT/ICDT), 2022. - Semantic Segmentation of AIS Trajectories for Detecting Complete Fishing Activities
Song Wu, Esteban Zimányi, Mahmoud Sakr, Kristian Torp
In IEEE MDM, 2022. - Speed and energy consumption for electrical vehicles
Rodrigo Sasse David, Esteban Zimanyi, Kristian Torp, Mahmoud Sakr
In IWCTS (with ACM SIGSPATIAL), 2022. - Database Optimizers in the Era of Learning
Dimitris Tsesmelis, Alkis Simitsis
In IEEE ICDE, 2022. - Mobility Data Science (Dagstuhl Seminar 22021)
Mohamed F. Mokbel, Mahmoud Attia Sakr, Li Xiong, Andreas Züfle, Jussara M. Almeida, Taylor Anderson, Walid G. Aref, Gennady L. Andrienko, Natalia V. Andrienko, Yang Cao, Sanjay Chawla, Reynold Cheng, Panos K. Chrysanthis, Xiqi Fei, Gabriel Ghinita, Anita Graser, Dimitrios Gunopulos, Christian S. Jensen, Joon-Seok Kim, Kyoung-Sook Kim, Peer Kröger, John Krumm, Johannes Lauer, Amr Magdy, Mario A. Nascimento, Siva Ravada, Matthias Renz, Dimitris Sacharidis, Flora D. Salim, Mohamed Sarwat, Maxime Schoemans, Cyrus Shahabi, Bettina Speckmann, Egemen Tanin, Xu Teng, Yannis Theodoridis, Kristian Torp, Goce Trajcevski, Marc J. van Kreveld, Carola Wenk, Martin Werner, Raymond Chi-Wing Wong, Song Wu, Jianqiu Xu, Moustafa Youssef, Demetris Zeinalipour, Mengxuan Zhang, Esteban Zimányi
In Dagstuhl Reports, 2021.
Public code repositories:
- Md Ataur Rahman (ESR 1.1)
- Yeasmin Ara Akter (ESR 1.2)
- Antheas Kapenekakis (ESR 1.3)
- Marcos (ESR 2.1)
- Uchechukwu Njoku (ESR 2.2)
- Abduvoris Abduvakhobov (ESR 2.3.)
- Song Wu (ESR 2.4)
- Antonios Kontaxakis(ESR 2.5)
- Eros (ESR 3.2)
- Ikhtiyor Nematov ESR 3.3
- Ibraheem Taha (ESR 4.1
- Daniele Lunghi (ESR 4.2)
- Christos Papadopoulos (ESR 4.3)
Contact Information
Application related questions: For all information about the DEDS programme, eligibility, and the application procedure please refer to the Application Manual. We kindly advise you to carefully follow the instructions from this document, while filling in your application.
For all additional questions regarding the application process, you are welcome to contact us at deds_admissions@cs.ulb.ac.be.
General questions: For information on the programme, mobility, relatioships with companies, and any general question please contact us at deds@cs.ulb.ac.be.
Final Event
| Time | Activity | Presentations |
|---|---|---|
| 8:50 - 9:00 | Welcome speech | |
| 9:00 - 10:30 | WP1 | Md Ataur Rahman, Text Data Integration Akter Yeasmin, Data Fusion Kapenekakis Antheas, Scalable, Privacy-aware DBMS Data Synthesis |
| 10:30 - 10:50 | Break | |
| 10:50 - 12:50 | WP2 | Uchechukwu Njoku, Comprehensive Approaches to Feature Selection in Machine Learning Abduvakhobov Abduvoris, Model-based storage for time series Song Wu, AIS-based Ship Trajectory Data Kontaxakis Antonis, Optimization techniques for Data Science |
| 12:50 - 13:50 | Lunch | |
| 13:50 - 15:20 | WP3 | Sasse David Rodrigo, Trajectory Data for Traffic Analytics Eros Fabrici, Privacy-Preserving Blockchain-Based Federated Learning Nematov Ikhtiyor, Intent-Aware and Faithful Example-Based Explainability in Machine Learning |
| 15:20 - 15:40 | Break | |
| 15:40 - 17:10 | WP4 | Ibrahim Taha, Table Search in Data Lakes: Methods, Indexing Techniques, and Challenges Lunghi Daniele, Adversarial machine learning in security applications Christos Papadopoulos, Approximate and Adaptive methods for Inference Queries over Unstructured Data |
| 17:10 - 17:30 | Break | |
| 17:30 - 18:30 | DEDS book | |
| 18:30 - 19:00 | Closing words | |
| 20:00 | Santa Clara Restaurante, address | |
The final event will take place at UPC.
The room will be Sala Agora.